
O que é Continuous Integration
Continuous Integration (ou Integração Contínua) é o processo de automatização da integração de código durante o desenvolvimento de software. A intenção desse processo é minimizar os possíveis problemas com a atualização do software a nível de código. Na prática, a integração contínua permite, de forma sistemática e automatizada, a identificação da maioria dos bugs, a padronização do código e, consequentemente, a produção de um código de maior qualidade.
O processo de integração contínua tem uma relação direta com a qualidade do software disponibilizado. Além disso, influencia diretamente o dia-a-dia do desenvolvedor pois, dependendo de como for configurado, auxilia na realização de atividades como:
- Produção de testes automatizados
- Aumento da cobertura de código avaliada nesses testes
- Padronização de escrita de código
- Outras que variam de acordo com o projeto e a equipe que o mantém
Como funciona na prática?
Depois de entendermos a importância desse processo para a qualidade do software e do time, agora nós vamos te contar todas as etapas que envolvem essa automatização.
Etapa 1: Formatação de código
Essa etapa visa a formatação de código seguindo algumas regras pré-definidas. Muitas vezes, é completamente automatizada, fazendo com que não seja necessário nem a confirmação do desenvolvedor para que ela seja realizada.


Etapa 2: Execução dos testes automatizados
Nesta etapa, todos os testes automatizados devem ser executados para identificar possíveis erros na aplicação. Assim como a formatação, essa é uma etapa que geralmente não necessita do aval do desenvolvedor para ser executada. Entretanto, diferentemente da formatação, ela não altera o código, apenas indica problemas que ele pode ter.
Uma atividade super comum realizada juntamente com a execução dos testes automatizados é a validação de cobertura de testes. A cobertura de testes diz respeito à representatividade do código por meio dos testes automatizados. Na prática, esse conceito avalia quanto do código foi executado enquanto os testes eram processados. É comum que projetos que trabalham com cobertura de testes imponham a necessidade de uma porcentagem mínima de cobertura para que uma alteração seja aceita e fundida ao código original.
Etapa 3: Construção da aplicação
Essa etapa é responsável pela compilação da aplicação e validação da construção da imagem para futuras implantações.
A imagem de um software é um objeto que permite a fácil implantação dele, sendo representado por um estado do disco de um computador com sistema de arquivo. Um exemplo aqui, para ficar mais claro, é o próprio Windows: quando você faz o download pela internet, você está baixando uma imagem dele que, por sua vez, é um conjunto de arquivos necessários para rodar o Windows, em geral no formato ISO - que é muito utilizado para disponibilização de imagens de discos óticos (como CDs, DVDs, Blu-ray).
Essa etapa é feita, em especial, para aplicações que são implantadas utilizando algum tipo de virtualização. Além disso, a construção dessa aplicação depende muito da maneira como ela é implantada quando colocada para uso pelos seus usuários.
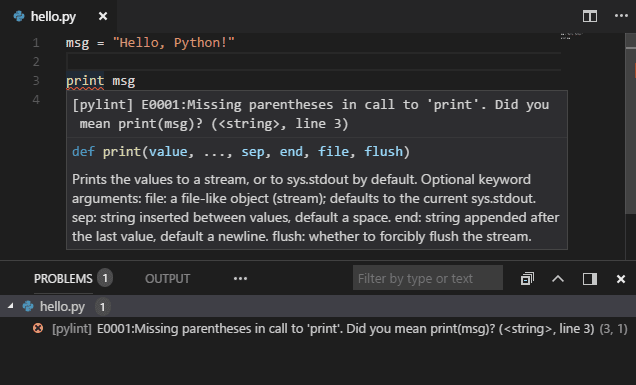
Etapa 4: Análise de código estática
Essa etapa tem como função a verificação e o aviso de erros comuns realizados por programadores. As aplicações que fazem essa atividade são conhecidas como Linters e estão completamente relacionadas com a linguagem de programação adotada pela aplicação. Assim como na formatação de código, é possível definir quais regras devem ser adotadas pelo Linter na hora da sua execução.
O que é Continuous Delivery & Deployment
Continuous Delivery & Deployment (ou Entrega e Implantação Contínua) é o processo de automatização da criação das versões de um software, bem como a disponibilização delas de acordo com as atualizações que ocorrem nele. A entrega e implantação contínua está completamente relacionada a um ambiente de implantação, assim como às atualizações que ocorrem nos softwares.
Um dos principais benefícios desse processo é a velocidade com que o software é disponibilizado para seus clientes e usuários. Isso porque o uso de entrega e implantação contínua diminui o intervalo de tempo entre a produção do código e a disponibilização dele através do software para o usuário final. Essa diminuição de tempo acontece, também, pois a cada mudança no código fonte da aplicação (como a correção de um bug ou a adição de uma nova funcionalidade), um gatilho é ativado para a implantação dessa atualização no oferecimento dessa aplicação.
Como funciona na prática?
Assim como o uso da Integração Contínua, esse outro processo é essencial para manter a qualidade de sua aplicação, bem como torná-la cada vez mais competitiva no mercado. Por isso, a seguir iremos te mostrar as etapas importantes da Entrega e Implantação Contínua.
Etapa 1: Disponibilização da nova versão
Nesta etapa, é realizada a construção da versão para futura implantação.
Etapa 2: Implantação da nova versão
Nesta etapa, a versão disponibilizada pelo Continuous Delivery deve ser colocada no ar para o uso de seus usuários.
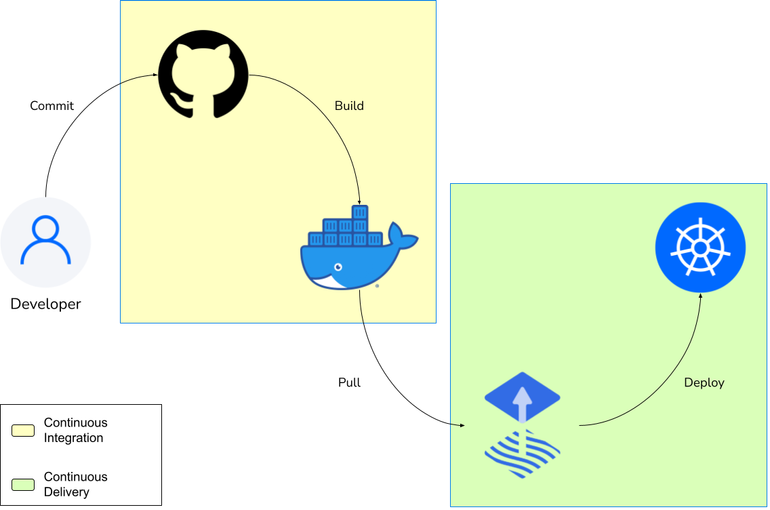
Como Continuous Integration e Continuous Delivery & Deployment interagem entre si
Toda etapa pertencente ao processo de desenvolvimento de software pode ser representada como sendo pertencente a Integração Contínua ou pertencente a Entrega e Implantação Contínua. Não só isso, esses dois processos são complementares e a união deles equivale, basicamente, a todo o processo de desenvolvimento de software, quando corretamente implementados.
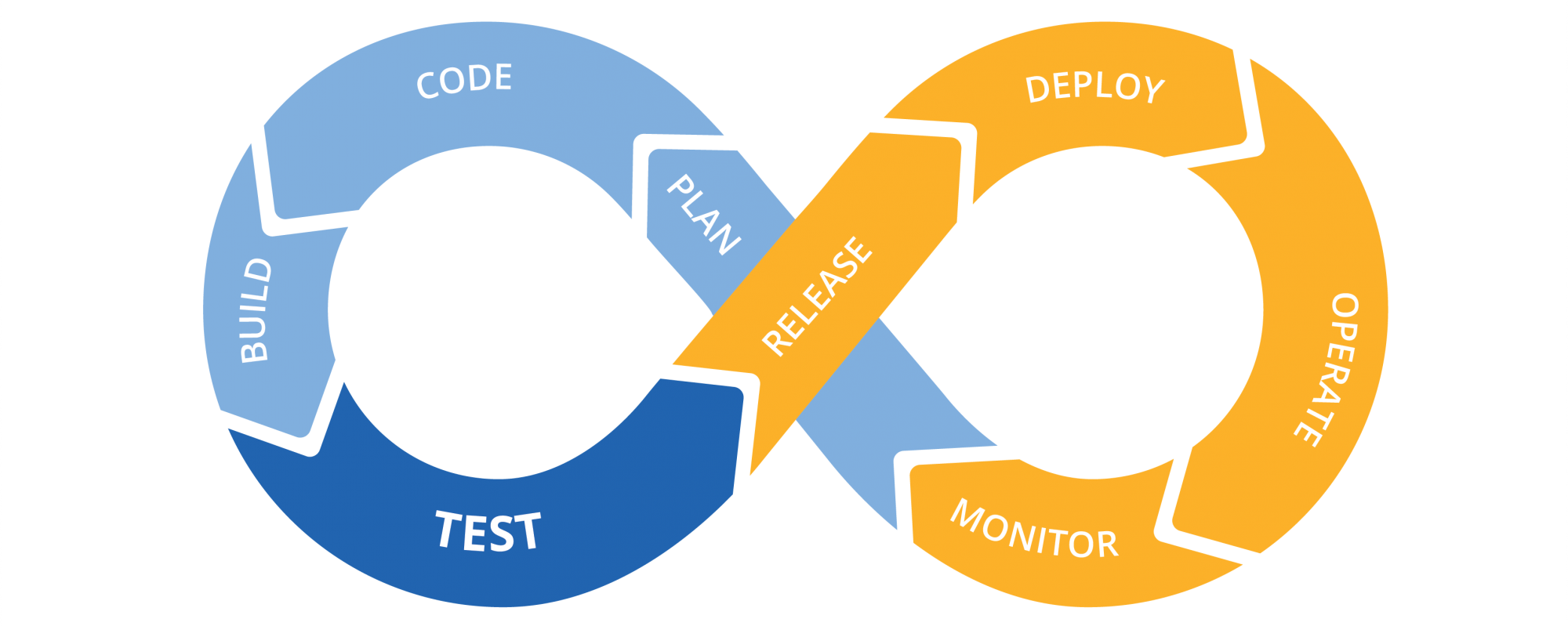
Na prática, a Integração Contínua prepara o código para alguma coisa implantável e a Entrega e Implantação Contínua pega essa coisa e a disponibiliza para uso em um ambiente apto a receber interações de usuários finais.
Um ponto importante é que isso não significa que um processo ocorre antes do outro. Na verdade, a execução de cada processo alimenta a próxima execução do outro processo. Dessa forma, assim como a Integração Contínua prepara uma atualização em algo implantável, a Entrega e Implantação Contínua permite a obtenção do feedback dessa atualização, que, por sua vez, alimenta o processo de decisão para futuras atualizações.
Ferramentas comuns
Docker Hub
O Docker Hub é um registro de imagens Docker. Considerando o significado de imagens visto acima, imagens Docker são imagens para serem executadas em containers Docker. Containers Docker funcionam como máquinas virtuais, mas são mais leves, visto que só armazenam os dados de mais alto nível (não guardam informações do sistema operacional, por exemplo) — o que os fazem muito úteis para diminuir o uso de recursos na nuvem e, consequentemente, os gastos com ela.
Voltando ao Docker Hub, ele funciona como um armazém de imagens Docker. Nele você consegue publicar e baixar imagens dispostas no registro.
Em relação ao CI/CD, o Docker Hub pode ser utilizado para realizar a etapa de building de imagens a partir de repositórios Git automaticamente. Para isso, o desenvolvedor deve configurar regras que indiquem o momento em que o Docker Hub deve começar a construir a imagem (como a criação de uma nova tag no repositório, por exemplo) — note que essa é uma funcionalidade da versão paga do serviço.
GitHub Actions
O GitHub Actions é uma aplicação para criação de fluxos de software, onde estão incluídas as etapas que compõem o CI e o CD. Essa plataforma funciona como uma espécie de executor de ações (ou actions), que é definido através de código, permitindo que o desenvolvedor execute sua aplicação a partir de gatilhos configurados por ele.
Em relação a CI, o desenvolvedor pode construir um fluxo para executar todos os testes automatizados da aplicação e indicar caso algum deles falhe, formatar os arquivos automaticamente a cada alteração no código fonte e executar o linter, por exemplo.
Já para o CD, é possível construir fluxos para fazer o build da aplicação e publicá-la em algum repositório para acesso futuro (como no Docker Hub, para imagens Docker) ou até mesmo atualizar a aplicação final (aquela que o usuário final pode interagir) diretamente.
Jenkins
Jenkins é um servidor de automação de código aberto que suporta a construção, implantação e outros dos diversos passos contidos num pipeline (fluxo) de CI/CD.
É uma das ferramentas mais utilizadas para configuração desse tipo de pipeline, possuindo uma comunidade gigantesca.
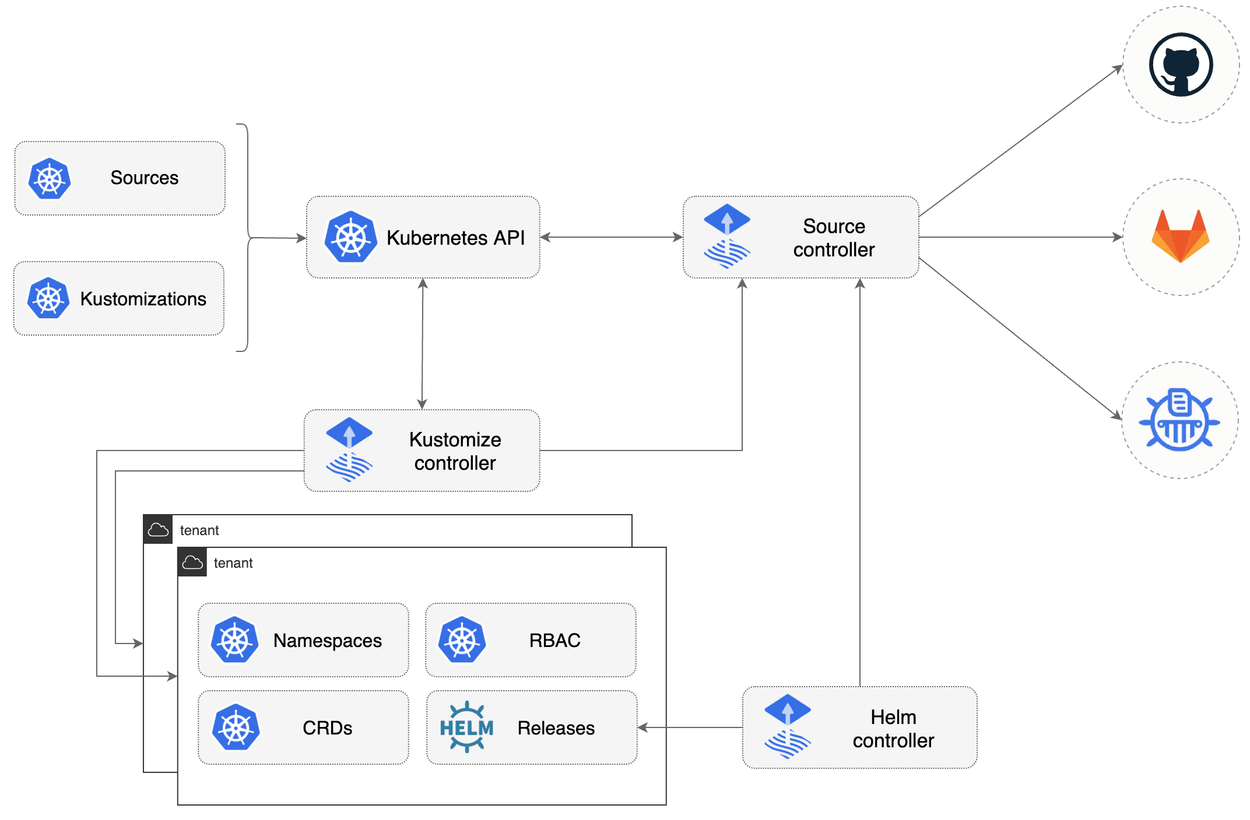
Flux
O Flux é um conjunto de soluções de implantação para Kubernetes baseado em Git. Ele faz o uso de um repositório Git para identificar o estado desejado para o cluster Kubernetes, realizando as alterações necessárias para que o cluster represente esse estado desejado. Dessa forma, toda alteração no repositório será automaticamente mapeada dentro do cluster sem a necessidade de interagir com ele diretamente (entrando na máquina e fazendo as operações).
Além disso, ele também permite o fluxo contrário: ele mesmo atualiza o estado desejado do cluster de acordo com configurações prévias como repositórios Helm ou Docker.
História de caso: Mconf e Elos
Por que começamos este trabalho?
Todos os dias as aplicações da Mconf sofrem alterações no seu código fonte, assim como qualquer outra empresa de tecnologia. Entretanto, estávamos notando dois tipos de problemas um tanto quanto comuns após o desenvolvimento:
- Erros que eram passíveis de verificação não estavam sendo verificados durante o desenvolvimento - fazendo com que fossem percebidos apenas em ambientes reais, afetando o serviço de alguma maneira;
- Assim que uma versão ficasse pronta, as atividades para colocá-la no ar eram completamente manuais e passíveis de automação, o que tomava tempo da equipe. Para atualizar uma aplicação, a pessoa precisava de acesso ao ambiente que, por sua vez, é um ambiente Kubernetes. Como não gostaríamos que os desenvolvedores das aplicações precisassem desse background para realizar as atualizações, entendemos que seria conveniente a construção de uma maneira mais intuitiva para realizar essas atualizações.
Esses dois pontos foram os norteadores para o início do trabalho de implementação de um pipeline de CI/CD. O primeiro problema, entretanto, só é resolvido parcialmente com uma implantação desse tipo de pipeline. O motivo para essa parcialidade é que não eram todas as aplicações que possuíam um conjunto de testes significativo, o que fazia com que a validação automática (através dos testes automatizados) não fosse suficiente, embora o pipeline também auxiliasse quanto a questões como padrões de formatação.
Dessa forma, além dessa automação na execução dos testes já existentes, também foi necessário realizar um trabalho de construção de testes automatizados para abranger uma porcentagem maior do funcionamento das aplicações e, por sua vez, ter uma confiança maior no resultado da execução dos testes.
A segunda questão tem dois vieses: um mais operacional, visto que é necessário acessar a máquina que hospeda a aplicação de alguma maneira para realizar a troca de versão, e o outro mais gerencial, visto que, além de atualizar a máquina, também precisávamos atualizar as nossas anotações que indicavam o estado de cada cluster (qual versão está rodando em cada ambiente para cada aplicação, por exemplo).
Utilizando um pipeline de CI/CD que, de alguma maneira, exponha o estado do ambiente, foi possível manter esse monitoramento de versões de maneira automatizada.
Arquitetura do pipeline
A nossa implementação se baseou em três ferramentas essenciais:
- GitHub Actions
- Docker Hub
- Flux
GitHub Actions
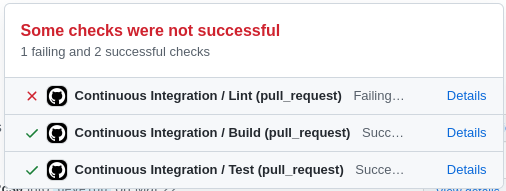
Com o uso do GitHub Actions, nós construímos todo o nosso CI. Através desta ferramenta, cada aplicação irá rodar automaticamente o formatador de código, os testes automatizados e o build da aplicação, informando ao desenvolvedor se houve algum problema com essas validações (algum teste falhou, o código não está formatado corretamente ou a aplicação não está sendo construída adequadamente).
Formatação
A formatação foi feita através de ferramentas específicas para cada linguagem de programação utilizada. No nosso caso, a maior parte das aplicações é escrita em GoLang e, para elas, decidimos utilizar o golangci-lint, que é um agregador de linters, contendo diversos linters importantes como indicadores de código repetido, código possivelmente problemático e muitas outras coisas de acordo com a configuração da ferramenta.
Build
Algumas aplicações precisam de uma etapa de building antes de serem colocadas em execução (como é o caso das aplicações que usam GoLang). Por este motivo, nesta etapa validamos se não está ocorrendo algum problema de compilação do código fonte.
Testes
Nesta etapa ocorre a execução dos testes automatizados. Se um dos testes automatizados não executar como o esperado, a mudança não pode ser aceita e o desenvolvedor deve corrigir o problema indicado pelo teste ou atualizá-lo de acordo com a alteração proposta.
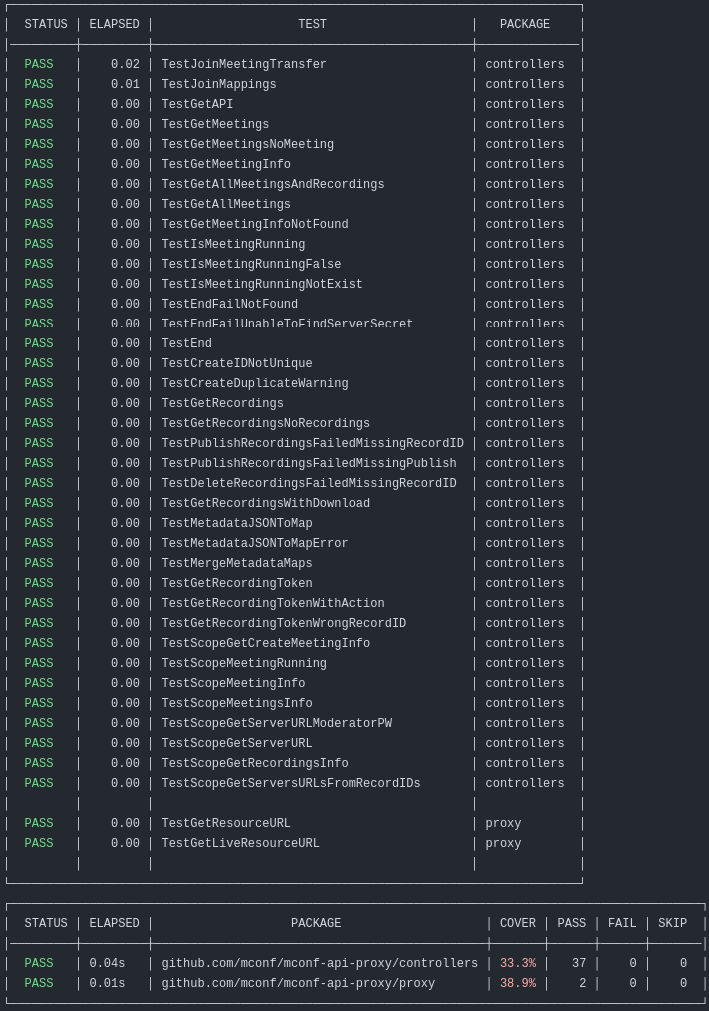
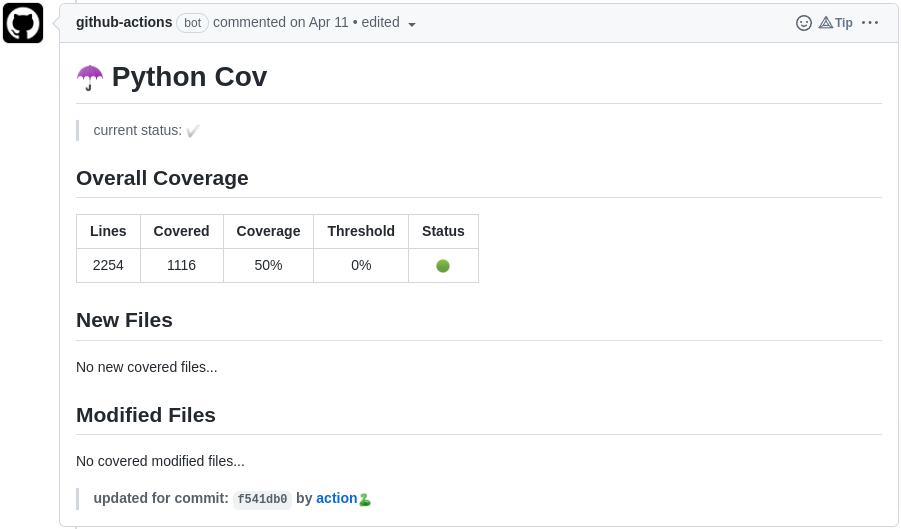
Além disso, uma etapa muito importante relacionada aos testes é a validação da cobertura de testes — embora tenhamos desativado-a visto que nosso conjunto de testes ainda não é representativo o suficiente.
Docker Hub
Utilizamos o Docker Hub para fazer o build da imagem Docker e colocá-la no registry. Para isso, utilizamos a funcionalidade de build automatizados, que é uma funcionalidade da versão paga do Docker Hub.
Cada nova versão criada no GitHub ativa um gatilho no Docker Hub que faz com que ele comece o build da imagem. Para isso, foi necessário configurar um repositório no Docker Hub apontando para o repositório do GitHub e esperando por novas tags no formato versionamento semântico (v1.3.2, por exemplo).

v(.*) — que significa qualquer texto que inicie com a letra v — e construindo imagens nomeadas com a mesma versão indicada na tag no repositório Git.Flux
Com as duas outras ferramentas nós temos as partes de integração contínua e de entrega contínua completas. Para a implantação contínua, decidimos utilizar uma ferramenta especialmente adequada para ambientes Kubernetes: o Flux.
Como explicado anteriormente, o Flux tenta colocar o ambiente em que ele está acoplado no mesmo estado indicado pelo repositório Git que ele monitora. Para a nossa felicidade, nós já utilizávamos um repositório Git para manter o estado dos clusters, mas essa operação era completamente manual. Então, nós só precisamos adaptar um pouco as coisas para que se conectassem perfeitamente com o que o Flux espera receber.
Entretanto, o Flux não faz só mudanças a partir do repositório Git. Ele também consegue sugerir mudanças neste repositório que, devido ao motivo anterior, serão refletidas no estado do cluster caso sejam de fato realizadas. No nosso caso, esse comportamento é utilizado para atualizar as imagens Docker utilizadas pelas aplicações. Assim sendo, sempre que uma imagem nova chega a um repositório que o Flux está monitorando, ele sugere a atualização das aplicações que utilizam essa imagem para a sua mais nova versão.
Organização de permissões
Após a implantação do pipeline descrito acima, surgiu um pequeno problema: agora que uma mudança no repositório é refletida em uma mudança operacional no estado do cluster, como decidir quem pode ter acesso a este repositório - em especial de escrita?
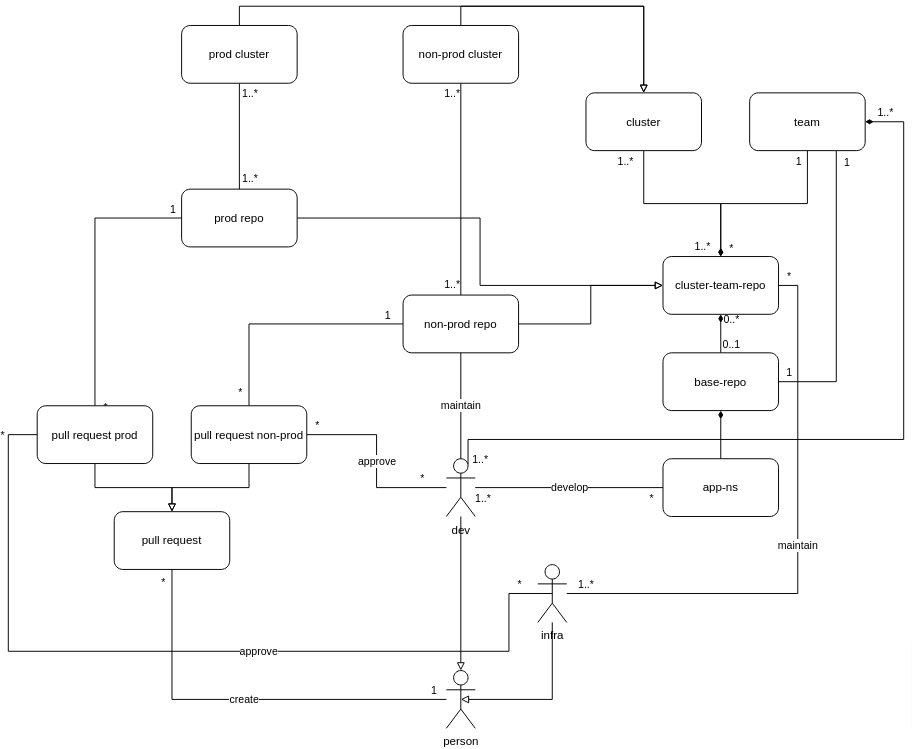
Empresas de tecnologia comumente possuem dois tipos de times técnicos (sob a ótica de infraestrutura): times de desenvolvimento de aplicações relacionados diretamente ao produto ou a regras de negócio que permeiam o produto; e times de infraestrutura que garantem a qualidade dessa infra para hospedagem das aplicações dos outros times.
Dessa forma, decidimos que o mais adequado era deixar a administração de repositórios que afetam ambientes de produção sob a responsabilidade das equipes de infraestrutura - e, portanto, essas equipes teriam acesso de escrita nesses repositórios.
Já para as equipes de desenvolvimento, decidimos que elas apenas teriam acesso de escrita em repositórios que representam ambientes seguros para alterações não finais, como os ambientes de homologação. Assim, a equipe de desenvolvimento possui uma grande flexibilidade para testar novas versões nesses ambientes intermediários e também fica garantido que nenhuma alteração não-intencional do serviço seja feita em ambientes de produção.
Referências:
- https://prettier.io/
- https://code.visualstudio.com/docs/python/linting
- https://blog.telexarsoftware.com/continuous-integration-continuous-delivery-part-1/
- https://fluxcd.io/
- https://github.com/features/actions
- https://jenkins.io/
- https://hub.docker.com/
- https://golangci-lint.run/
- https://github.com/marketplace/actions/python-cov
- https://docs.docker.com/docker-hub/builds/